
Welcome to part two of this blog series. In the first part we’ve explored the current state of the pharma industry and how the regulatory submissions process has been impacted. We’ve looked at KPIs that sponsors and CROs can monitor to ensure regulatory submission success, and we’ve analyzed the current landscape, looking at the internal and external challenges organizations face when creating regulatory dossiers under tight deadlines.
Going forward, we will define the key areas organizations must assess to leverage technology optimally, transforming both regulatory content processes and the working lives of staff.
New ways of working
In part one, we’ve identified the challenges organizations face when producing regulatory content. Now let’s explore how organizations are changing the way they do business as to overcome these obstacles.
1. Address volume overload and resource strain
Regulatory and clinical teams tackle high-complexity, high-volume content that changes rapidly. At the same time, pharma businesses are under pressure to drive down costs. Maintaining regulatory documentation and staying within budgets becomes a difficult, if not impossible task, if medical writers or other editors continue to utilize tools that lack the necessary structure to deliver data-driven outcomes, address issues like lack of access to good information, siloed functions and difficulties collaborating on documents. Many organizations are working off a tangled web of documents and documents that help users navigate the file title and the content it holds.
Technology is critical in sustainably accelerating regulatory submissions.
Source: Rewiring pharma’s regulatory submissions with AI and zero-based design, McKinsey’s, 2025
Everyone on the same page: centralizing documentation
Organizations are adopting modern tools to help their teams scale content creation from trials to submissions. The first step is to move beyond tools that are not fit for purpose. To manage high volumes of content, regulatory teams need tools with strong versioning capabilities that can pinpoint changes to the document from one version to another. Instead of relying on a generic folder-sharing system, regulatory teams need the capabilities to centralize documentation in a single platform where they can easily find what they are looking for by performing a search or by asking an AI chatbot to quickly provide the latest approved version.
2. Eliminate manual, document-intensive content creation
Let’s return to the medical writer who is navigating folder chaos. Now they have a more critical task: updating a 1,000-page-long document. They must correctly identify all sections, snippets and data instances that must change in accordance with the latest updates.
This often requires a highly manual lift, addressing hundreds of changes and no system for validating that each edit is captured, no way to compare against the old version or double-check your work.
In the scenario where a document moves past the reviewers and they, too, miss the issue, this will lead to cumulative delays in submitting the dossier.
Reducing manual effort: GenAI-assisted drafting
To solve the issue of intensive, error-prone manual labor, organizations can turn their attention to generative AI solutions. With templates, AI-assisted drafting, automated formatting and style guide checking, organizations can streamline writing, reviewing and publishing complex documentation.
You might ask: can I trust AI to create a first draft? How can I ensure this draft contains accurate information? The answer is: feed your AI tool accurate content in a structured fashion. You’ve noticed that even if you upload validated documents into your AI system, you’re still getting gibberish in the draft it creates. And the only reason you notice this is because you are reading the generated AI draft and are comparing it against the original documents it drew content from. Why is this happening? Shouldn’t have AI solved my problem?
Documents may have a visible structure defined by chapters, sections, tables and other elements, however, utilizing generic tools, this is a structure that often only addresses human needs. To unleash the capabilities of AI tools and generate ‘first time right’ documents, you must feed it content that is machine-readable. In other words, you need to give your AI structured content.
Early pilots show that gen-AI-assisted medical writing can help reduce the end-to-end cycling time for authoring of clinical-study reports (CSRs) by 40 percent.
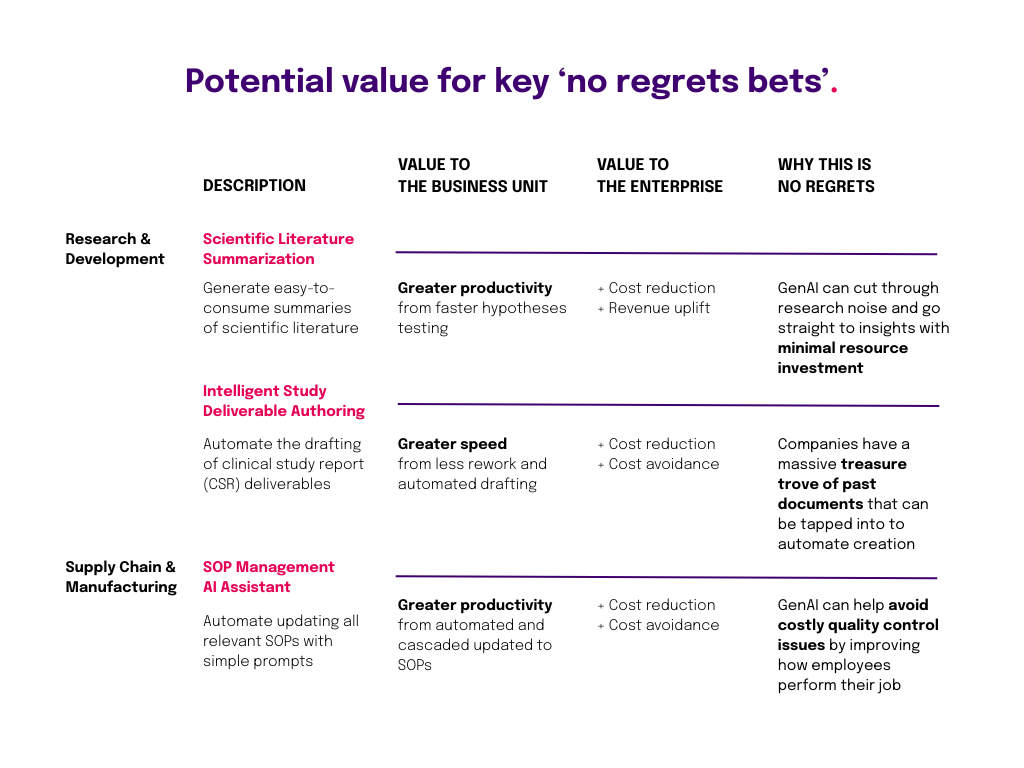
Source: Realizing Transformative Value from AI & Generative AI in Life Science, Deloitte, 2024
3. Break down data silos and faulty data flows
Data silos are the result of various factors such as legacy systems, multiple data sources and department fragmentation. As organizations grow and assimilate other groups, they find themselves in the middle of a vast body of data and knowledge that resides in various disjointed systems that have been meticulously soldered together to the brink of inefficiency.
Teams working across various systems often feel the pain that these integrations might not work as needed; for example, it might take a long time to process requests. It might just not work altogether. Teams may be burdened with documentation that needs to be updated manually once the new data is available. But it often happens that because there is no system notification on new data being available in, let’s say the Laboratory Information Management System (LIMS), teams simply overlook updating the documentation, translating into the documentation being rejected by regulatory authorities.
Joining up the dots: End-to-end regulatory data and content integration
Pharma organizations need an enterprise-wide unified data platform to support data-centric submissions workflows. This is achievable through a radical modernization of core technologies used from protocol development to submission.
A modern data management technology stack can help organizations to:
- Pull content from the original source for data tables, figure legends, and standard statistical methodology descriptions.
- Maintain consistency across multiregional submissions while allowing for region-specific adaptations.
- Integrate new data into existing document structures for studies quickly, eliminating the need for manual content changes.
- Shorten authoring and review cycles, as writers can choose to automatically propagate pre-approved content across the documentation, without needing to go through re-validation.
- Skip verifying regulatory-required pre-defined content such as disclaimers or other standard mandatory content pieces.
- Facilitate AI orchestration by enabling holistic, end-to-end infrastructure alignment and technical readiness
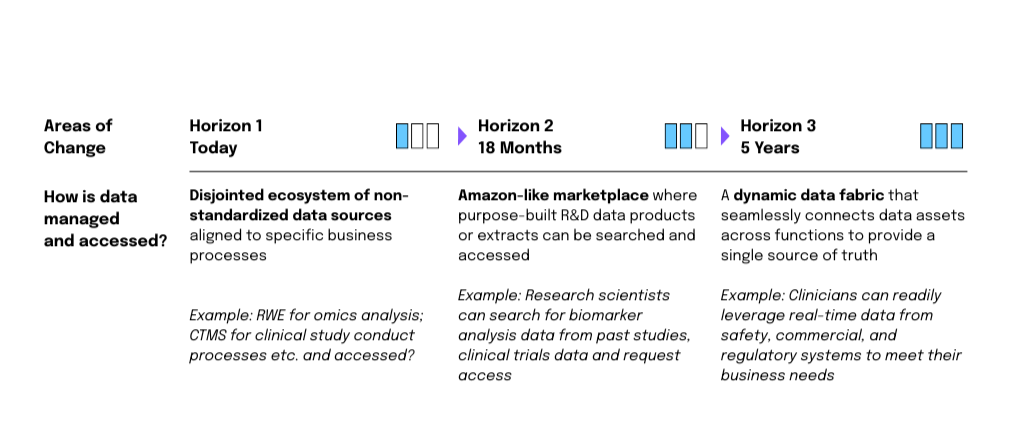
Source: 2024 Global Life Sciences: Driving resiliency, Deloitte, 2024
4. Mitigate risks associated with errors in complex multi-country submissions
Pharmaceuticals are most often marketed in several countries with different official languages and different regulatory conditions. This implies two aspects:
- Regulatory submissions need to be translated clearly, so that they can be properly understood by every user and regulatory body, and
- The content needs to be adjusted to the specific template that each regulatory authority requests.
Prioritizing accuracy and efficiency: AI-driven translation capabilities
Formatting and translations are notoriously complex and time-consuming. Once teams automate data flows, they can create and use smart templates for each regulatory document. These smart templates can pull in data from any data source, while working from a single source of truth.
With an AI and structured content approach, teams can reduce translation times as much as 50%. This is achieved via:
- A single platform for managing all language versions. All language versions are stored in the same content management platform with makes it easy to manage and update them. Because these platforms work with structured, modular content, it’s easy to send any or all vetted content pieces (components) to translation and then integrate them in the correct localized document version.
- Precise, time-saving translation. Instead of localizing entire dossiers, translators can manage granular pieces of content, substantially reducing cost. This approach also reduces delivery time for the translation teams, as it helps them pinpoint what needs to be translated.
Embracing a data-centric paradigm
Around the world, regulatory authorities are mandating the transition to structured, machine-readable regulatory content. This is targeting quality improvement in submissions, real-time data exchange with sponsors and CROs, shortened review cycles and AI-driven efficiency gains. Among these regulations and initiatives, some notable mentions include: ICH M11, eCTD 4.0, SPOR/IDMP, the EMA data-centric Target Operating Model (TOM), the FDA Real-World Evidence initiative or CDISC.
By replacing outdated core technology with modern, AI-ready, integrated systems, such as structured content authoring (SCA) and structured content management (SCM), alongside regulatory information management systems (RIMS), pharma organizations can enable a data-centric approach that replaces the old paper-based document paradigm.
AI-enabled structured content conforms to predefined rules, which prevents AI from hallucinating. Content is stored and managed centrally and can be accessed internally by any department or person, given they have access rights, or externally by collaborating regulatory authorities. Once all the information is vetted, the content can be translated, formatted and delivered in the right output, be it XML, FHIR, PDF, Word or other, to your RIM.
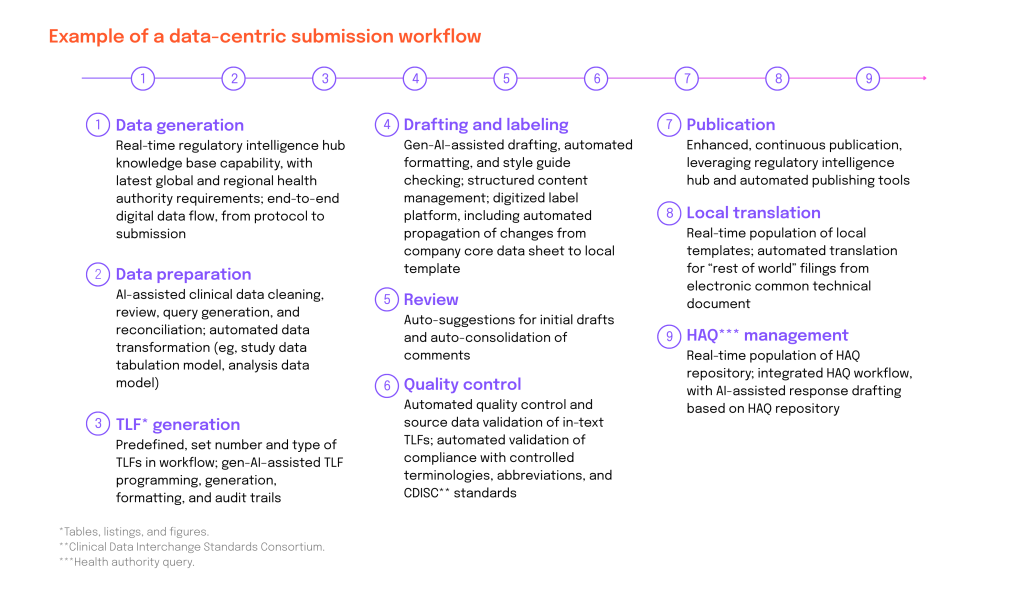
Source: McKinsey & Company
Your checklist for AI-ready and data-centric submissions
Here is a quick checklist for content compliance readiness from our solutions team:
- Do we have a single source of truth for our most critical compliance content (or is it copy-pasted in many places)?
- Can we update all instances of a given regulation-driven statement quickly (or would we have to search through dozens of files)?
- Is every piece of our documentation tied to an owner and an approval record (or do documents “float” without clear accountability)?
- During the last audit or review, did we struggle to find documents or evidence of approvals? Audit trail available? (Yes/No)
- Are translations of our compliance content centrally managed and in sync with the source text (or do different regions end up with diverging information)?
- Does our documentation process include automated checks (for missing sections, out-of-date content, broken links), or is it entirely manual proofreading?
- If a new law or standard comes out today, do we know which documents would need updating? (In other words, do we map content to specific regulatory requirements?)
- Finally, do content contributors and reviewers have an easy way to collaborate without version confusion (or are we emailing Word drafts back and forth)?
If you encountered some “no” answers, it’s a strong sign that moving toward a structured, AI-enabled approach to documentation will bring immediate benefits.
Next, perform a gap analysis for your organization to know where you stand:
- Identity the scope and objectives
- Review current regulatory requirements
- Assess internal documentation and connected processes
- Identify gaps and set your list of priorities
- Develop a risk-based action plan
Change is inevitable. At RWS, we understand that adopting a data-centric approach to documentation is more than a tech upgrade. That’s why our tools and support structure are designed to help your teams transition from documentation bottleneck to best practices.
Ready to explore what AI and structured content could unlock for your organization?
If you are interested in discussing in more detail data-centric approaches to regulatory submissions or how to best perform an effective gap analysis for your regulatory content, you can contact the Fonto One team here.

Product marketeer for Tridion and Fonto One at RWS