
Fonto Editor
The online XML editor, designed for people with no knowledge of XML or any other technology that comes with structured content authoring.
You only get one chance to make a first impression
Let us introduce our flagship product.
Popular features
Thousands of authors worldwide use Fonto to create structured content in many different languages.
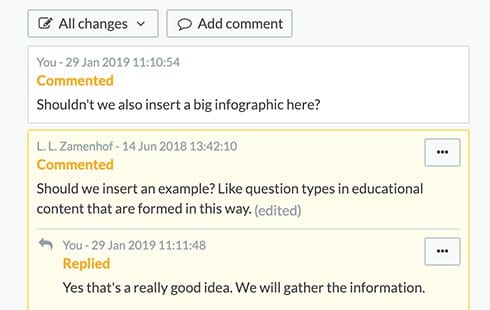
Comments
Working on a document together? You can easily leave your comments and gather feedback in Fonto. When reviewing content with many different people, Fonto Review provides an effective solution.
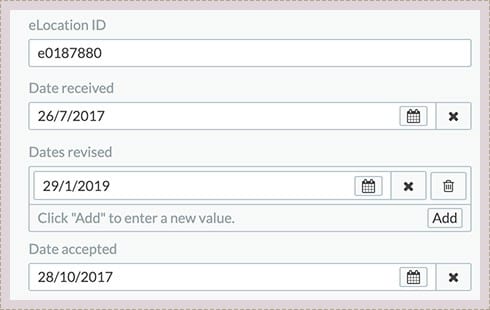
Metadata
Fonto provides authors a clear and user friendly interface to create and manage metadata on a fine grained level. Artificial intelligence starts here.
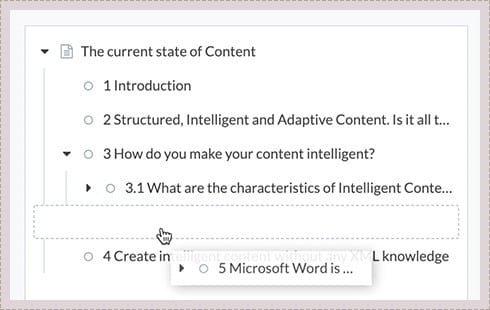
Drag & Drop
Restructure and organize the document layout by simply dragging the outline elements into your preferred arrangement. This works for complete chapters and individual paragraphs.
Copy & Paste
Authors can cut, copy and paste content from Word, PDF or HTML, using the familiar keyboard shortcuts. When pasting in Fonto, the text on the clipboard is inserted, keeping paragraphs and line breaks where we can recognize them from the source format.

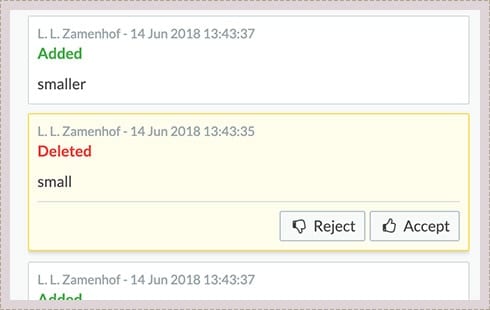
Track Changes
We track textual changes the way Microsoft Word does. To keep track of structural changes Fonto Document History is a powerful complementary tool.
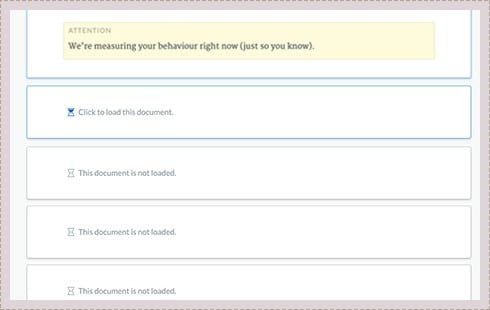
Supports Large Documents
Fonto can handle the heavy stuff at high speed: aircraft manuals, ISO standards, clinical trials and legislation. Publications of over 400 pages, 60.000 topics and gigabytes of data, we’ve done it.
Real-time Validation
When you create, edit or review content, every change is validated in real-time. Fonto makes sure you can only create valid content compliant with the XML schema in use. Whether that’s a standard schema like DITA, JATS or S1000D, or your custom XML schema.

Easy Integration
Fonto’s open architecture makes its easy to integrate with existing digital asset management systems, (enterprise) content management systems and repositories.

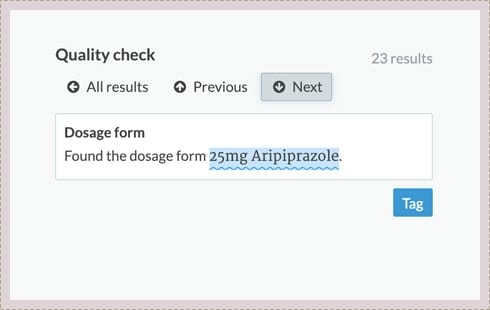
Entity Recognition
Fonto can recognise and (semi) automatically classify predefined terms and entities. Using Fonto Content Quality a wealth of semantic knowledge can be created in real-time, based on those recognised metadata.
Customizable UI
Fonto enables you to create the best possible user experience for authors. Designers, developers and authors all benefit from a balanced, flexible component library.
Multiple Documents
For schemas that define document sets (e.g. DITA maps), Fonto provides commands to add or remove documents to and from a collection, changing the order of documents within a collection, as well as changing their level within the hierarchy.
Linking to taxonomies
To let an author refer to terms in a predefined taxonomy, an API offers an endpoint to retrieve suggested terms that autocomplete the author’s request.
Publication Previews
To give authors a good feel of what they are working on, Fonto can provide previews of the different publication formats: HTML, PDF, E-books, Learning platforms, Magazine’s, Manuals, etc.
Localization
The Fonto Editor enables authors to work with documents in left-to-right writing systems. Also IME is supported. The language used in the interface of the editor is US English.
Tables
Creating and editing tables in Fonto is a piece of cake. For very large tables we have some extra features available, so authors will keep a good overview.
Non-textual Content
The Fonto Editor enables authors to insert images, audio, video, presentations and more. Fonto can play file formats supported by your browser immediately.
Formula Support
The Fonto Editor enables authors to easily create quality math formulas using the MathType editor by WIRIS that is integrated into Fonto.
XML Schemas
The Fonto Editor supports all XML Schemas. Each schema can be integrated, DITA, JSON, JATS, or a custom XML schema.
Crosslinking
Depending on the schema you’re using, Fonto makes it easy to link to specific (existing) parts within a document.
Find & Replace
The Fonto Editor enables authors to easily find and replace words, just like in Microsoft Word.
External resources
We make it easy for authors to link to external resources. Under the hood Fonto requests a permanent ID for each document or asset to make sure references are properly managed.
Graphical Interactions
For users that want to play around with graphical interactions, we’ve got the tools to do so. Create your own heat maps or graphical question types. It’s all there.
Unicode
The Fonto Editor enables authors to use Unicode characters and symbols in their documents.
Try Fonto For Free
We can spend a 1000 words on how intuitive Fonto is
but why don’t you find out for yourself!