
In this weekly series, Martin describes a question raised by a Fonto developer, how it was resolved and why Fonto behaved like that in the first place. This week is a follow-up to an earlier blog post on dealing with large documents! How did we chunk megabytes of XML?!
This post is a follow-up to the blog post that explains how you can chunk up documents in a generic way to make them work with Fonto. This post will make that concrete for the NISO Standards Tag Suite.
We have partners working with NISO-STS and have implemented chunking before. This blog post tells this story and the outcome.
What is NISO-STS and why are we chunking?
ANSI/NISO Z39.102-2017 Standards Tag Suite (STS) is a standard for the XML encoding of standards documents, to share them. STS provides tags for Standards and Adoptions of Standards, Errata and Corrigenda and other normative documents.
A standards document can be large and contains many sections. Some of the example documents we use for testing our solution contain more than two thousand tables. Others contain almost three thousand sub-sections. Without chunking, the whole publication will be locked as one item and can only be edited and saved as one big document. With chunking, we meet two important criteria for the NISO-STS schema:
- authors can collaborate on the same publication by working on individual chunks.
Chunks can now be used as the most granular level on which a part of the publication can be locked to avoid collisions during collaborative editing with multiple authors. - authors can quickly edit a whole publication, even when the whole publication contains many thousands of pages. By not loading the whole standard when it is not needed, the load time is dramatically improved. This is further explained in the earlier blog post on dealing with large documents.
Authoring schema
We use a different schema in Fonto editor with some small changes to improve the authoring experience in the Fonto editor, without changing the actual NISO-STS schema. This means that these rules come on top of the NISO-STS schema, and we need a pre-/post-convert to make sure the content on the CMS is still compliant with the NISO-STS schema.
The schema used during the authoring phase differs from standards-compliant NISO-STS in the concept of “chunking” – breaking a publication down into chunks in such a way that the original publication can be reconstructed.
Another part where the authoring schema differs from the standard is in cross references. In normal STS, only the id of the target of the reference is used. This is not sufficient when a document is chunked. When a cross-reference (the xref element in NISO-STS terms) references another chunk, that chunk must be loaded to make the reference resolve. We encode the id of the chunk in which the reference resides to make this work. In the editor, we then call a custom endpoint of the CMS that gives us a preview of the reference: the title of the reference and anything else we render.
Because the schema only allows “IDREF” for the rid attribute. We replace the attribute with an “as:rid” that we add to the schema. So we can add the remoteDocumentId in the link attribute.
The chunked XML is assembled into a fully compliant NISO-STS document before it is exported to external systems. Similarly, any NISO-STS document imported into the solution can be disassembled into appropriate chunks.
Chunking
When Fonto opens a standard, the CMS breaks down the full publication into smaller chunks. The CMS then only serves an outline document that contains references to the individual chunks, combined with their titles. When Fonto then attempts to load a single chunk, such as the foreword, the CMS only responds with the foreword. Should the author then use the outline to jump to a section further down, Fonto only loads that section, plus the sections around it.
The individual section chunks can then be edited by multiple authors at the same time. When it comes to collaboration this is an improvement over loading the whole publication as a single file, in which only one author can be active at once.
When saving the document, the CMS gets only the chunk that is changed. This changed chunk is merged into the entire publication. When an author changes the outline of the publication by moving sections around, the CMS also applies those changes to the entire publication.
NISO-STS can contain references to elements using the xref element. Those references may point to chunks that are not loaded. Fonto could load the document that the reference points to resolve the reference information. However, this can cause many document loads. Instead, we recommend using the CMS to retrieve that information. See the cross-references section for more information.
Chunk references
The hierarchy of a publication is expressed through the hierarchy in which references to individual chunks are placed. For example, to model three sections and two subsections:
<as:sec-ref href="sec_1" />
<as:sec-ref href="sec_2" />
<as:sec-ref href="sec_3">
<as:sec-ref href="sec_3.1" />
<as:sec-ref href="sec_3.2" />
</as:sec-ref>
There are two phases in chunking: assembly and disassembly. The assembly phase is responsible for applying changes to individual chunks to the original publication. The assembly phase is also responsible for applying changes to the outline document back to the original publication: if an author indents or outdents a section, that should also be done on the whole publication. If a section reference contains another section reference, the assembly phase is responsible to place the other section in the correct place. We chose to place sub-sections at the end of their parent section.
For example:
<as:sec-ref href="sec_3"> <as:sec-ref href="sec_3.1" /> </as:sec-ref>
Becomes:
<sec id="sec_3">
<title>Section 3</title>
<!-- Paragraph, list and other content from section 3 -->
<sec id="sec_3.1">
<title>Section 3.1</title>
<!-- Paragraph, list and other content from section 3.1 -->
</sec>
</sec>
The nesting of chunk references is ultimately determined by the set of elements that are considered “chunkable elements”.
Chunk types
A distinction can be made between “content chunks” and “structure chunks”.
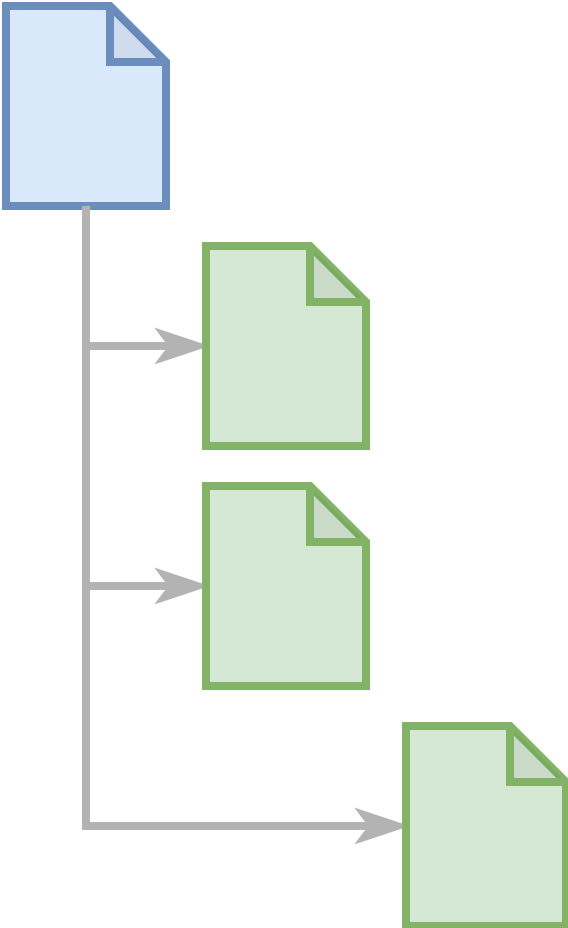 A “structure chunk” (in blue) contains a hierarchy of references to content chunks (green) A “structure chunk” (in blue) contains a hierarchy of references to content chunks (green) |
- Content chunks: XML documents that have a title and content but do not include additional chunks or chunk references. A content chunk can have one of several different top-level elements.
<sec xsi:noNamespaceSchemaLocation="authoring-schema" id="sec_3.1"> <label>B.3.1</label> <title>Methodology</title> <p>The sample should be selected partly based on the…</p> </sec>
- Structure chunks: XML documents that arrange any amount of content chunks or structure chunks in order and act as a vehicle for transporting cross-cutting information. The top-level element of a “structure chunk” can be a <standard> or <adoption> element.
<standard xsi:noNamespaceSchemaLocation="authoring-schema">
<front>
<!-- Code example is truncated for brevity -->
</front>
<body>
<as:sec-ref href="sec_1" />
<as:sec-ref href="sec_2" />
<as:sec-ref href="sec_3">
<as:sec-ref href="sec_3.1" />
<as:sec-ref href="sec_3.2" />
</as:sec-ref>
</body>
</standard>
This allows Fonto to get an index of all the required chunks, and to retrieve the minimum required metadata to populate a user interface, in a single web request.
The top-level structure chunk must not refer to other structure chunks, or more specifically, content chunks must not also function as structure chunks. As an effect only one person can make changes to the publication outline at a time; inserting, removing and moving chunks/sections.
Content chunks
An element is eligible to act as a content chunk if all of the following criteria are met:
- Must be a block-level element.
- Must not be allowed to contain other elements eligible as chunks, or must only be allowed to contain them as an uninterrupted (possibly hierarchical) sequence at the end of its content model.
- Is itself referred to from a content chunk, or is referred to from the structure chunk.
This makes a wide range of elements eligible as content chunks, such as <p>. This is technically possible but not ideal for user experience. The following additional criteria are applied loosely to narrow down the list of eligible chunk root elements:
- Should be a semantic unit of information and/or a logical division of labour between authors.
- Should have a label or title by which it is commonly cited, or which is used in the “table of contents”/outline view.
- Should contain block-level elements such as paragraphs, lists and tables, rather than mixed content.
Sections are obvious candidate chunk root elements. According to an initial analysis of the content models in NISO-STS, there may be up to 24 other elements similarly suitable for chunking. Some of these elements introduce concepts that can not logically be represented in a Word-like document, such as a section placing paragraph text after a subsection (for example, <sec> embedded in <boxed-text> at a random point in another <sec>). Depending on to what extent this must be a supported use case, the level of chunking becomes more or less granular.
It could be that in some cases the choice depends on the direct parent of the section. For example <sec> is also allowed in <abstract> in this case it can’t be a chunk. In NISO-sts we decided to not allow sections in abstracts in the authoring schema, seeing as there was no use case for it.
Assembly and disassembly
The CMS (or middleware application) is responsible for the conversion of NISO STS documents to and from the NISO STS authoring schema. The NISO STS authoring schema is a so-called chunked schema which roughly means that each section within a document becomes a separate XML file. Such a section is referred to as a chunk. Chunks play an important role in collaboration, access control and just-in-time loading (JIT-loading) features of the authoring solution.
The process of breaking up a NISO STS document into its parts is called chunking or disassembly. The process of stitching back together all the chunks into a NISO STS is called assembly. Both processes must be implemented in the CMS or the middleware application.
This component is also responsible for just in time creation of the necessary cross-chunk information. The recommendation is to implement this as a just-in-time addition of this information in the GET /document and GET /document/revision endpoints.
To assemble a chunked publication into a standards-compliant NISO-STS document you can start at the root element and recursively process its contents:
- For every child of the context element:
- If it is not an element, leave the node untouched.
- If it is an element but not a chunk reference, recurse this function with the element as the context node.
- Else (it is a chunk reference):
- Replace the chunk reference element with the root element of the targeted chunk.
- Append all child nodes of the chunk reference to the chunk element.
- Recurse this function using the chunk element as the context node.
To disassemble a standards-compliant NISO-STS document into chunks:
- Create a new file for the chunk, and insert a new empty element with the same name and attributes as the context node.
- For every child of the context element:
- If it is not an element, move the node into the chunk element.
- If it is an element but not a chunkable element, move the node into the chunk element and recurse from step 2 by using this element as the context element.
- For any cross reference (eg. <xref>) in this new chunk, replace the reference attribute with information that can identify the chunk that contains the target element.
- Else (it is a chunkable element):
- Recurse from step 1 by using this element as the context element.
- Replace the chunkable element in its original context with a new chunk reference to the chunk.
Implementation notes
The section Outline and Numbering lays out which information from content chunks needs to be indexed into the structure chunk. The authoring solution will not update the structure chunk if any of that index information is modified within an instance of Fonto because it would lead to lock contention on the structure chunk. Therefore it is not recommended to store the indexed information in the database. Instead, it is recommended to synthesise the indexed data just in time in the implementation of GET /document and GET /document/revision endpoints.
The recommended implementation approach is:
- Implement a data structure which holds the indexed data keyed by chunk identifier.
- In the POST /document and PUT /document endpoint handlers for the content chunks, update this data structure.
- In the GET /document and GET /document/revision endpoint handler for the structure chunks, perform a linear scan over the XML. For each reference to a content chunk, perform a lookup by content chunk id in the data structure and create the required sub-elements.
A keen reader may observe that this means that the authoring solution may display stale results to an author. The authoring solution should get its information from the content chunks directly. This information is guaranteed to be up to date. If a content chunk is not loaded, which often happens in the case of JIT-loading, the information is retrieved from the structure chunk which may be stale. It is important to observe that an author can never see stale results based on their own actions because authors can only make changes when a content chunk is loaded. A document that the author changes will not be unloaded.
Outline and numbering
The outline document needs to contain more than just the structure of the document. It also needs to include the titles of the chunks that are referenced. This allows Fonto to display a useful “table of contents” UI without needing to load all chunks shown in it.
<as:sec-ref href="sec_B.1">
<as:outline>
<title>Introduction</title>
</as:outline>
</as:sec-ref>
The outline element should contain the elements of the chunk that are also used in the outline view of the editor. This means for “as:sec-ref” and “as:term-sec-ref” the “title” element will be used. But for “as:term-sec-ref” the “tbx:term” element. Only one tbx:term element is allowed in “as:outline” so if there are multiple, the first (preferred term) should be used.
<as:term-sec-ref href="sec_3.1">
<as:outline>
<tbx:term>antenna</tbx:term>
</as:outline>
</as:sec-ref>
To assemble chunks into a valid NISO-STS document, a reference of type <sec-ref> must always resolve to a <sec> element, a reference <term-sec-ref> must resolve to <term-sec>, and so on.
In our NISO-STS solution, we request the CMS for information we need to number tables and figures. The CMS responds with a summary of all documents in the standard, loaded or not. This data includes a minimised structural representation of the XML content. This data is then used in our XQuery engine to calculate numbering for either loaded or unloaded content.
In the case of tables, in unloaded documents, we use the CMS data to count how many table elements there are in a document, for loaded documents we use the XML directly.
An example of such data can be found below:
"chunks/id-4ff03454-a692-4fbe-8bb4-7b6d36fab4ef.xml": {
"nodeName": "app",
"attributes": {
"content-type": "inform-annex",
"id": "id-4ff03454-a692-4fbe-8bb4-7b6d36fab4ef"
},
"children": [
{
"nodeName": "fig",
"attributes": {
"id": "id-79d4750d-1862-4b7e-ec60-38aa829dc87a"
},
"children": []
},
{
"nodeName": "table-wrap",
"attributes": {
"id": "id-4531d274-20ba-47a7-8884-1836f7e38898"
},
"children": []
}
]
}
Cross-references
A NISO-STS document is required to only have xref@rid values that also occur as an identifier for another element in the same document.
For the authoring schema that means that only cross-references to the same chunk are valid, as well as cross-references to elements within another chunk that is part of the same publication.
In the authoring schema, it now becomes important to see which chunk contains the referenced elements, since they may not be from the same chunk. For the formatting of this reference, inspiration can be taken from the <xi:include> element referencing, which is already part of the NISO-STS schema.
For example:
sec-1.xml#fig-1 chunks/sec-5464-4367-2772-3465.xml#id-bbcd-436b-b3fd
Extensibility
In principle, the schema can not be changed unless that change is adopted by the NISO-STS working group. The authoring schema is a derivative of NISO-STS so can be changed almost only under the same circumstances.
In cases where a schema change is preferable over compliance with the NISO-STS standard, a tenant can choose to transform their NISO-STS publication, outside the authoring solution or as part of the (dis)assembly process.
For example, switching the order of elements in <tbx:term> can be implemented in this way without requiring changes to the authoring solution itself.
Sub-chunk sibling content
Due to the replacements of section references within section references, the technical design does not automatically accommodate the case where a sub-section is followed by “normal” content such as paragraphs;
<sec> <sec /> <p /> </sec>
This information, disassembled, would get lost;
<as:sec-ref> <as:sec-ref /> </as:sec-ref>
This case is not solved by our technical design. We filter these elements out before chunking to regard these kinds of sections as one bigger section that is not chunked further.
One outline versus many?
One aspect of the chunked authoring schema is reconstructing the hierarchy in which sections, appendices and sections therein occur.
- One structure chunk to indicate the children and descendants for a whole publication.
- Many structure chunks refer to their direct children and other structure chunks so that structure chunks are recursively nested.
A solution that involves one structure chunk was chosen. This chapter provides a rationale for that choice.
Comparison
- One structure chunk is less complex than many structure chunks as there is no need for recursion, managing multiple chunks or affecting multiple documents when a hierarchy change is made. This is considered a strong argument for the one-structure chunk solution.
- One structure chunk is a closer fit to the NISO-STS content model, as it allows any hierarchy level to contain text as well as child chunks. This is considered a strong argument for the one-structure chunk solution.
- Many structure chunks allow for granular locking and unlocking of the structure chunks at every level in the “table of contents”. This allows more concurrent authors to make changes to the high-level publication structure, but it does not affect authoring paragraphs, tables, lists, references, etc. However, not many concurrent changes to the “table of contents” are expected, and the problem can be avoided with further development (eg. automatic unlocking or conflict resolving). All things considered, this is a weak argument for the many structure chunks solution.
- Many structure chunks allow for more granular access control. This could be used to prevent authors from changing the hierarchy of sections to which they are not assigned. However, this is not a known requirement. Moreover, authors can be prevented from making such a mistake in the one-structure chunk solution too, albeit with some additional development to the tool. All things considered, this is a weak argument for the many structure chunks solution.
- One structure chunk requires fewer HTTP calls to be made to load the full outline. However, this can be negated by grouping related documents in a request for the root-level structure chunk, which is a feature already developed by Fonto and is compatible with either one or many structure chunks. All things considered, this is a weak argument for the one-structure chunk solution.
Alternatives
A hybrid solution where essentially two XML representations of the publication outline were kept was briefly considered.
Conclusion
The comparison above favours the one-structure chunk solution. The drawbacks of this solution are not fundamental; they can be avoided or solved with a more sophisticated UI and stricter timing around releasing a lock. One advantage of many structure chunks is granular access control, which can still be implemented through Fonto configuration (configuring an element as read-only under certain circumstances) or input checking in the CMS.
Chunkable elements
This chapter specifies which elements must be chunked when converting a NISO-STS document to the authoring schema. The specification is given as an XPath test, to more precisely quantify the scenarios where an element of the same name may not be chunked. Although the specification is given as XPath it can be implemented in any programming language capable of processing XML.
Erroneous chunking may lead to visual bugs in Fonto, or the inability to display (and therefore edit) a chunk in Fonto. The chunking algorithm itself, seen separately from displaying it, would not lead to data loss.
Also using the predicate is-chunkable() to refer back to this list for recursively nested elements.
Current chunk elements
| Type of chunk | XPath test |
| Appendix | self::app[ |
| Body | self::body[ |
| Footnote group | self::fn-group[ |
| Front matter | self::front[ |
| Index | self::index[ |
| Reference list | self::ref-list[ |
| Section | self::sec[ |
| Standard | self::standard[not(parent::*)] |
| Term section | self::term-sec[ |
Please note that any parent where an element may occur is purposefully omitted if in that situation the element should not be chunked. For example, <sec> may occur in <boxed-text> but is not chunked there.
This blog post explained how we built an architecture that can easily load big documents. We covered how to enable JIT loading by chunking. We touched on how we number documents and tables in unloaded documents. We made cross-references work and we explained how to build an assembly and disassembly phase. This blog post does not yet explain how to set up a custom hierarchy implementation. This has a reason! In the 8.4 release, we are introducing a new API to configure these hierarchies in a declarative way, so expect a follow-up to this blog-post that explains how we configure that!
I hope this explained how Fonto works and why it works like that. During the years we built quite the product, and we are aware some parts work in unexpected ways for those who have not been with it from the start. If you have any points of Fonto you would like some focus on, we are always ready and willing to share! Reach out on Twitter to Martin Middel or file a support issue!

Developer advocate / Evangelist. Has been with Fonto since it all began in 2013. He’s currently designing the next steps in Fonto Developer APIs with the input of our valuable partners.
In his spare time, Martin is an avid home brewer.
Stay up-to-date
Fonto Why & How posts direct in your inbox
Receive updates on new Fonto Why & How blog posts by email