
A question that was raised by a Fonto developer, how it was resolved and why Fonto behaved like that in the first place. This week, a partner found their editor to slow down while typing!
A support request came in:
When we load a huge document, we notice a significant slowdown in just about everything. Mainly typing gets slow, but any operation is slower. Can you tell us what’s up? We attached the editor and a big document in which the slowdown is very noticable
A Fonto partner
After loading the editor, it is indeed very slow. I performed a performance profile which indicated a whopping 479ms block of rendering content.

m.update function calls are renders. There are multiple small m.update blocks in the wider animation frame fired block. This means multiple separate views are rerendering, which is odd for a normal keystroke. From experience, if multiple views are rerendering, the culprit is usually XPath. I picked up the instructions in the blogpost on XPath performance to see what’s up.
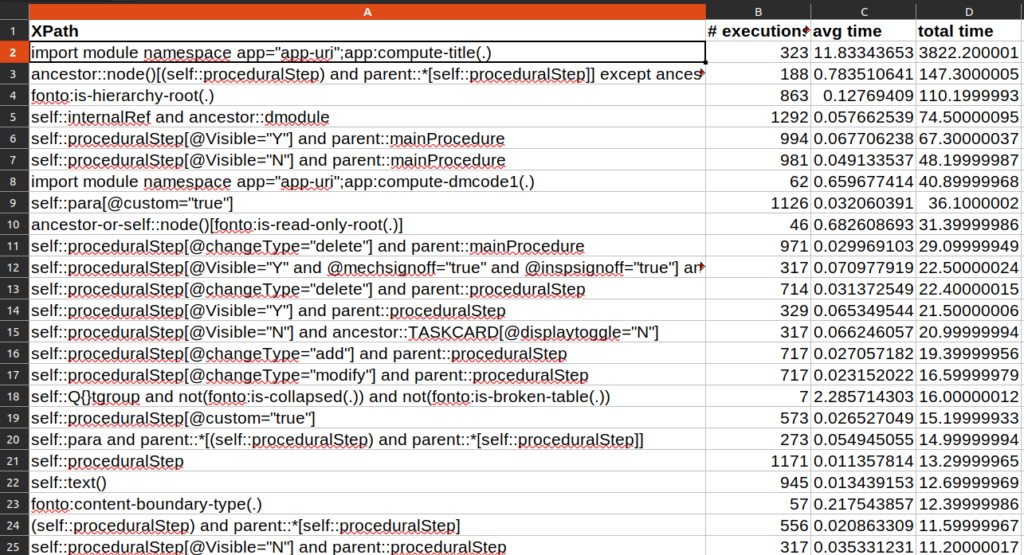
Let’s look at the implementation of that function:
declare %public function app:compute-title ($node as element()) as xs:string {
let $href := $node/@href
let $root := $node/ancestor::root
let $referredNode := $root//*[@id=$href]
return (: Omitted for clarity :)
};
This function looks quite simple, but one thing looks strange: the $root//*[@id=$href]. Because the $root element is in this schema one of the top-level elements, this turns out to basically scan the whole document. While XPath is quite fast, this should not matter too much if it is done only once. However, the function is used in an template. The template will take a dependency on the childlists of the elements in that root element. If any of these child lists are altered, the template will rerender for that node, which causes a significant performance delay.
By following the guide outlined for addAttributeIndex, I implemented an attribute index. The attribute index indexes all elements on their id attribute. It creates a function that accepts a string and returns all elements that have that attribute set to the requested value. This is usually a single element, but to be sure only elements in the $root element are resolved, I applied it like this:
declare %public function app:compute-title ($node as element()) as xs:string {
let $href := $node/@href
let $root := $node/ancestor::root
let $referredNode := app:root($href)[ancestor::root[. is $root]]
return (: Omitted for clarity :)
};
After that, a new profile shows an improvement!
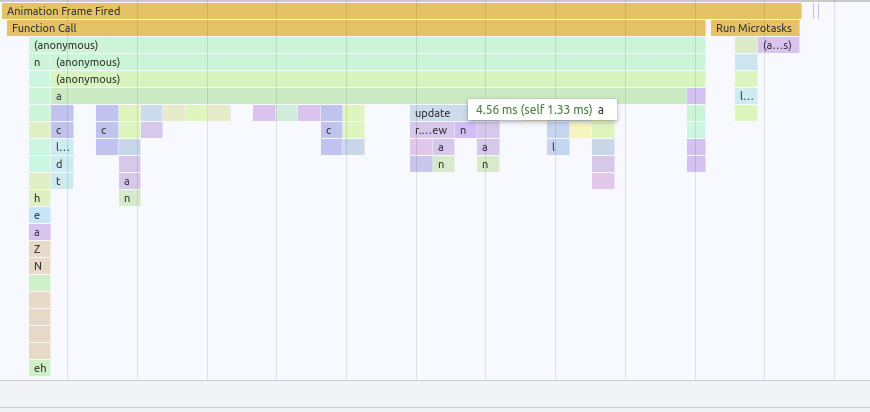
But why?
But why was Fonto so slow? Why did the // cause a full rerender? To answer this we need to look at how Fonto works in rendering. We’ve covered this a bit in a blogpost of a partner whose templates were not updating at all. Summarized, a template rerenders for a node whenever something changed in the XML (or in an external value). It tries to minimize this by recording which XML nodes are actually touched by the template.
In the case of a //*[@id=$href], this query is expanded to descendant-or-self::node()/child::element()[attribute::$href]. Especially the descendant-or-self::node() is annoying; it also includes any text node or processing instruction that is anywhere. Meaning that whenever a PI is inserted, the whole query is invalidated and the template is scheduled for rerendering.
Inserting text usually only changes the value of a textnode. But not when the track-changes add-on is enabled; it will insert processing instructions that track this insertion. While we are definitely looking to improve the performance of these queries and their dependencies, setting up an index for attributes is always a good idea. Inserting new elements will always have to invalidate these descendant queries. It may be that a new element that is inserted contains a new element that has an id set to a value we are interested in.
I hope this explained how Fonto works and why it works like that. During the years we built quite the product, and we are aware some parts work in unexpected ways for those who have not been with it from the start. If you have any points of Fonto you would like some focus on, we are always ready and willing to share! Reach out on Twitter to Martin Middel or file a support issue!

Developer advocate / Evangelist. Has been with Fonto since it all began in 2013. He’s currently designing the next steps in Fonto Developer APIs with the input of our valuable partners.
In his spare time, Martin is an avid home brewer.
Stay up-to-date
Fonto Why & How posts direct in your inbox
Receive updates on new Fonto Why & How blog posts by email